RISECampに参加した
10/11–12にUC BerkeleyのRISELabが主催していたbootcampに参加しました。kawasaki.rbでも少し話しましたが、参加報告です。雰囲気は公式FBの写真がわかりやすいです。
RISE Camp - RISE Camp
_RISE Camp is a bootcamp organized by the UC Berkeley RISELab where you can get exposure to research and…_risecamp.berkeley.edu
動画とTutorial用のバイナリが公開されました
RISELabはSparkで有名なAMPLabの後継となる研究室で、彼らが作るML関連のライブラリ・フレームワークのハンズオンをするというのが会の趣旨です。
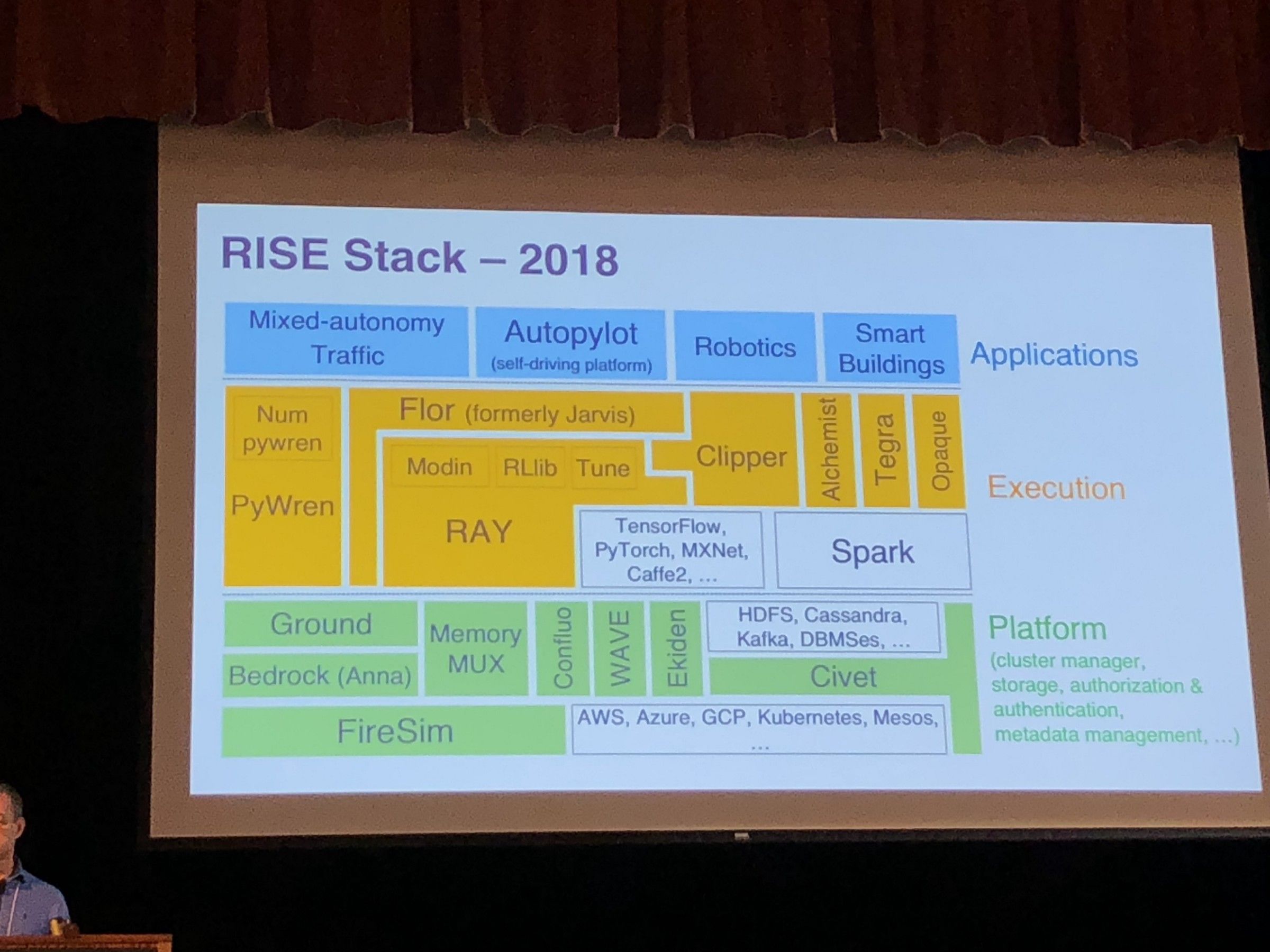
RISELabのStack
上の図のオレンジと緑の部分が彼らが作っているフレームワークになるのですが、その中でも以下のものについての紹介がありました。
- RAY, RLlib, Tune: Pythonの分散処理フレームワークRAYと、それを使った強化学習ライブラリRLlib、パラメータチューニング用のライブラリTune
- Flor: MLのモデル作成のための実験をtrackingするためのライブラリ
- Clipper: MLモデルのServing用のAPIサーバを立てたり管理するためのライブラリ
- PyWren: AWS Lambdaを使った並列処理のためのライブラリ
- Opaque: Apache Sparkを使った暗号化したDataFrameを処理するライブラリ
- WAVE: Decentralised authorization for IoT
tl;drという名の感想
- 機械学習エンジニアリングは複雑で、モデルのデプロイ・サービング、実験の再現性やトレーサビリティはプロダクションへの重要なパートになる気がする。MLFlowやKubeflowもそういったMLOpsの部分を狙っている
- 機械学習のワークロードはすべてPythonでやるぞという意気込みを強く感じた。会場からはSparkとどう連携するの?みたいな話もよく出たが、PySparkで一応…みたいな答えが多かった。特に cloudpickle を使ってオブジェクトばらまいて並列分散処理をすればいいじゃんという発想は単純ながら力強い。そして、Apache Arrowでノードのworker間のshared memory作るというのは今どきだなと。PythonはDSLとして便利なポジションになってるのかなぁ
たまたま、帰りの飛行機で聞いたTWML AI podcastでもこんな話が出ていました。
以下、ざっとハンズオンを行った順に紹介をしていきます。
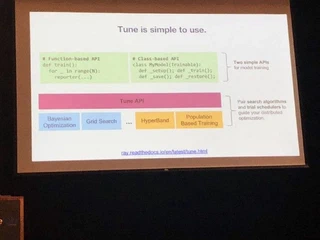
RAY, RLlib, Tune
RAYはこのRISELabのセットの中での基礎となるフレームワークです。READMEにもある通り、以下のようなdecoratorを書くだけでPythonの処理を並列・分散処理できるというコンセプトのものになります。
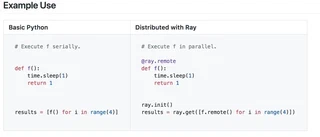
MLの処理をDSLとして抽象化します。特徴としては、
- FunctionをTasksとして
- ClassをActorsとして
として、Actorモデルを使って並列処理を行います。 @ray.remote というデコレータを書くと、その関数はRAYのWorkerで実行されるという仕組みです。
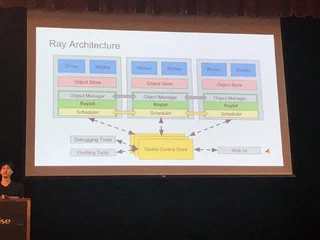
ポイントとしては、Pythonのobjectをcloudpickleというpackageを使ってserializeしてWorkerに投げてしまうということです。裏側にはノードごとのshared memoryとしてApache Arrowもいるため、Workerの共用メモリとしてオブジェクトを格納します。データの並列化どうするんだろうなと思ったら、ModinというPandas on Rayというライブラリも開発しているようです。”Modin is a DataFrame for datasets from 1KB to 1TB+”と言っているので、皆が困っているサイズ感のDataFrameを扱えるようになるかもしれません。
チュートリアルは、こちらのrepoと同じものを実際にJupyterLabでハンズ・オンしました。
RAY自体はなるほど、と思って生々しいコードを書いていたのですが、それをベースにしたRLlibという強化学習のライブラリとTuneというパラメータチューニング用のライブラリを使ってみて、隠蔽されたアプリケーションとして使うとML用の並列処理を行うのには良いなと感じました。
なお、WorkerのPythonのdependencyはあらかじめ解決した上で走らせてねということなので、複数プロジェクト走らせたりするのにはまだまだ自前で頑張る部分がありそうです。
Clipper
Clipperは、MLの予測のためのAPIサーバを簡単にデプロイできるようにするためのライブラリです。
コンセプトとしてはData scientistにパフォーマンスが気になる本番のAPI部分のコードを書かせることなく、スケーラブルなAPIサーバをコンテナベースでデプロイできるようにするということです。基本的には対応しているPythonのMLライブラリであれば、Dockerfileも書かないで予測の処理のコードを書いて、それをPythonからデプロイするという流れになります。
また、内部ではPrometheusのコンテナも立ち上げて、特定のmetricsをトラッキングできるようになっています。
Flor
Florは機械学習の実験のトレーサビリティを上げ、再現性を高めるためのライブラリになります。
機械学習では、feature engineeringなどのデータの加工をしたり、パラメータの探索をしたりしながらパイプラインを作っていきます。そこで、よくあるのが過去のパイプラインを再現したいのに、既にobjectが上書きされていて戻せないといったことがあります。Florでは、それを再現可能にするために色々と補助をしてくれます。
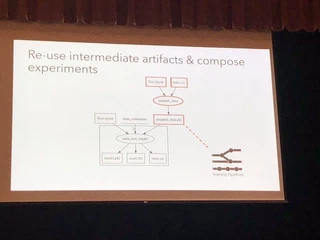
少しFlor流の書き方をしないといけないのですが、それをすることで実験同士の処理のdiffを見たり、処理のパイプラインを可視化したり、他の人から引き継いだ実験の中間データを後から再度取得したりすることができます。
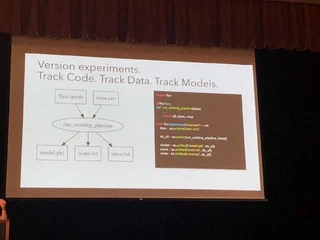
MLでは実験のreproducibilityをどう作るのかという話がよく話題にあがるため、その一つのアプローチとして良いのではないでしょうか。ただ、大きいデータになったときの中間データを効率的に保存できるかは少し気になりました。
PyWren
PyWrenは、AWS Lambdaのようなサーバレスアーキテクチャを使って並行処理を行うためのフレームワークです。(まだ、GCPやAzureでは動かないっぽい)
以下はパラメータチューニングのノートブックですが、mapとfilterで処理を並列にばらまくことで分割しています。
また、これだけではなくNumPyWrenというNumpyの処理を同様に並列化するというプロジェクトも進んでいるようです。
PyWrenに関してはLambdaのアップロードできるイメージ?のサイズの制限があるため、shared objectを外部サーバに出したりと充実したPython Package周りを入れるために工夫をしているようです。
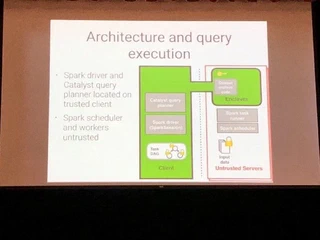
Opaque
OpaqueはSparkSQLをHardware Enclaves (Intel SGX, AMD SEV etc)の上で走らせて、セキュアな分析を可能にするものとのことです。チュートリアルでは、病気に関するデータセットを使ってSpark DataFrameを処理しましたが、まだScalaでしか動かないようです。
WAVE
IoTのための中央集権型ではない認可のための仕組みです。
RISECamp 2017の動画
チュートリアルでは、二人の人がペアになって、それぞれのスマートホームを模したライトや温度センサーに対して変更や読み取りの権限を与えて操作をするということを行いました。
これだけだと、なんでこの流れでこれが紹介されるの?と思いましたが、最後に行ったRay, Clipper, Flor, WAVEの統合ハンズオンでは、RayとRLlibでpongの強化学習を行うための予測モデルを作り、Clipperでモデルをデプロイし、更にそのモデルの予測のための権限をWAVEで管理するという形でした。予測モデルの権限管理をするという発想があまりなかったので興味深かったです。
スライドやVideoはまだ出ていませんが、当日YouTube Liveでも中継していたので、そのうち公式チャンネルに上がると思います。
あと、JupyterLab/Jupyter Notebookでのハンズオンを二日間フルでやりましたが、FIXMEを残しておいて修正したらassertでうまくいったかチェックをするというスタイルは、自分でも進捗を確認しやすいので良かったなと思います。

