RNNLMベースの形態素解析器 JUMAN++ をhomebrewでインストールできるようにした
京大の黒橋・河原研から最近出たJUMAN++をmacOSのhomebrewでinstallできるようにしました。
JUMAN++はRNNLMというディープラーニングベースの言語モデルを使っています。 こちらの記事を読んで知ったという方も多いのではないでしょうか。
新形態素解析器JUMAN++を触ってみたけど思ったより高精度でMeCabから乗り換えようかと思った話 - Qiita
インストール方法は、現段階では後述する理由のためhomebrew-coreにはまだ入っていないので、tapを使ってください。
[2016/10/23追記] やっと本家homebrewに入ったので、tapは要らなくなりました。 [/追記]
$ brew install jumanpp
github
JUMAN++のサイト凄い
JUMAN++のサイトには解析を試せるWebアプリケーションがあるのですが、それがなかなか面白いです。
この「どうも、julialang界の頑固おじさんです」というフレーズを解析した結果がこちらです。
こういうラティスを出力してくれます。
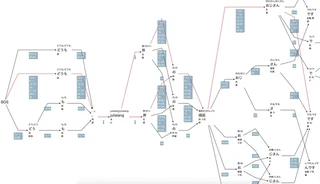
楽しい
JUMAN++とMeCabどっちがいいの?
冒頭のQiitaの記事に対してはRNNLMベースだからというよりは、辞書の改善によるものなのでは?という話はMeCab作者の工藤さんからも指摘があります。
これってほとんど辞書による改善だと思う...https://t.co/NnbXreOR48
— Taku Kudo (@taku910) October 13, 2016
@overlast さんが精力的に更新をしているneologdとの比較をしているため、MeCab側としては現在普通に入手可能なMeCabの辞書としては最も良いものを使っていると思います。 なので、neologd以前に良く問題とされていた「最近の用語が入っていない」という部分に関しては議論の対象にはなっていませんね。
表記ゆれや長音記号のハンドリングに関してはJUMANの頃からやっていたことです。 JUMANの頃からWikipediaを使った語彙獲得やオノマトペの処理など、未知語獲得を黒橋研として頑張っている印象がありました。
また、部分アノテーションか辞書かという話に関しては、以前から議論が分かれている所です。
形態素解析の分野適応は、「点推定+(部分)アノテーション」と「品詞付き単語追加」でどう違うのかという疑問を持ったので、それをつぶやいたところ、@zzzelch…
JUMAN++(の前のJUMAN)とMeCabの比較は以下が詳しいのですが、使っている文法が違ったりなど癖が違うので注意が必要です。
個人的にはneologdが頻繁に辞書を更新してリリースし続けている状況に対して、JUMAN++の側がどれだけの頻度で更新されたモデルが出せるというところが実用的な差になるのではないでしょうか。普通のエンジニアが部分アノテーションのためのコーパスを作り続けるのは、正直かなり厳しいと思います。1 JUMAN++の論文でも、4万5千文を再学習することで性能がMeCabを越えたと言っています。
現段階では、実際に比較をしてみてどちらが用途に合うのかを判断するのが良いと思います。
なお、読み推定がしたい場合はKyteaを使うといいと思います :)
homebrew-coreに入っていない理由
この記事を書いている段階では、upstream(v1.01)のMakefileにあるバグのため、makeに-jオプションを付与して並列でビルドすると失敗する問題があります。
このパッチを当てれば大丈夫です。
で、何故これがcoreに入っていないかというと、
- 特定のワークアラウンドが必要(並列ビルドを抑える
ENV.depararelizeを使う)な場合は、upstreamのissueを立ててそこへのリンクを貼る必要がある - juman++は2016/10/15現在レポジトリが公開されておらず2 、publicなissueがない
- homebrew-coreにはupstreamにマージされないパッチを当てるFormulaは受け入れられない
つまり、 homebrewでビルド時のバグが有り、かつpublicなレポジトリ(正確にはpublicなticketやissueなど)がない という条件下ではcoreに登録することはできないようです。 気持ちはわからなくもないけど、すべてGithubにissueがある(あるいは公開MLがある)という前提はちょっと不寛容じゃないかと思います。 Githubで公開されていることしか考えていないんでしょうかね…。
はじめての、新規Formula作成でしたがちょっと疲れました。。。
sugyanさんのアイドルコーパスも好きだから続けられると思っているし、それくらいコーパス作るの大変 ↩︎
じきにgithubかbitbucketに公開される予定とのこと ↩︎

