TinySegmenterをJulia移植したらMITの先生に指導してもらえた話
先日、工藤さんがJavaScript向けに作った日本語のコンパクトな分かち書きツール、TinySegmenterをJuliaに移植したTinySegmenter.jlを作りました。 もともとは、PyconJPでjanomeの話を聞いたら居ても立っても居られなくなって、簡単なTinySegmenterを移植したんですが、そしたら思いもよらぬ展開が待っていました。
[2015/10/22 23:38 追記] 計測の問題を @repeatedly さんから指摘いただいたので再計測しました。
パッケージ登録時にMITの先生からツッコミが入る
JuliaのパッケージはMETADATA.jlというセントラルなレポジトリで管理されています。 ここに登録されたパッケージはPkg.add("TinySegmenter")とREPLで実行するだけでパッケージが導入できます。1
ここに登録をしようとした時に、「日本語の分かち書きツールなのに、パッケージ名が一般的すぎるのでは」という指摘をMITの@stevengj先生(以下、SGJ先生)からいただきます。Juliaのパッケージの命名規則はドキュメントにもあるのですが、portingの時はそのまま名前を付けても良さそうなので反論をして、翌日マージされました。
パッケージ登録後、1週間ほぼ毎日issueが立つ
僕の初期実装はmhagiwaraさんのPython実装を参考に、割とベタに実装をしていました。
ですが、LLっぽい書き方で書いていたため、多くのツッコミどころがあったので、最適化したらどう?的なissueがぼっこぼこ立ちました。 プライベートのコードでこんなにissueもらったのは初めてだったのですごい嬉しい反面、一番多い時で夜寝る前に一個こなしては朝起きると次のissueが立ち、出社前に一つ片付けたら昼にもう一個増えるみたいな、時差をフル活用したハードな指導が始まりました。
最適化としては主に以下のような最適化をしました。
- const使おう
- RegexやめてCharに展開しよう
- DictのkeyはCharのTuple使おう
- Stringはコピーが発生するのでStringBuf使おう
日本語が読めないSGJ先生、オリジナル実装のバグを見つける
面白かったのは、途中で日本語が全くわからないSGJ先生2 がオリジナルの実装にバグを見つけたところ。半角カタカナの"グ"がUnicodeでは二文字になるはずなのに、それを考慮した実装になってないからスコアが反映されてない、という点。工藤さんにも確認しましたが、ご本人も昔のことなので詳細は覚えていないが今の実装は間違っていそうだという事を確認しました。 気づいた原因は、DictのkeyをCharのTupleで表現する関係で、文字数応じた型宣言をしていたからなんです。3
実際には、日本語の中で半角カタカナはほとんど出てこないのでそこまで影響は出ませんが、ASCII圏の力を思い知らされました。なお、ここの議論で日本語知らない人に英語で半角カタカナ全角カタカナの議論をする必要があり、泣きそうでした。 この頃にはPRも来ていたのですが、半角カタカナの"グ"は二文字だから"ク"じゃねーの?とか来ていたのも、今となっては良い思い出です。
SGJ先生の狙いは
「なんでこの人はこんなマニアックな日本語の分かち書きプログラムに、熱心にissue立てるんだ?」と謎に思いながら、毎日の宿題のようにこなしていたのですが、最後の課題 issueを見て納得します。
そう、ベンチマークだったのです。
おそらく、最初のパッケージ名反論の時に、「TinySegmenterは多数の言語で実装されており日本人には一般的な名前だ」と主張した時に調査し、気づいたのだと思います。
というわけで、Python実装のバグを見つけて直したり、Python3対応したり、Node.jsのファイルの読み込み方調べたりしながら、ベンチマークとりました。
その結果がこちら。(詳細はissueを見て下さい)
[2015/10/22 23:38 追記]
@repeatedly 先生が色々指摘をしてくれて、Pythonのループ回数が10分の1だったり、Juliaのコードが足りなかったり、Rubyの実装も高速化していただいたので計測しなおしました。 なお、D言語でのベンチはこれからです。
TinySegmenterのベンチマーク + D言語版 - Go ahead!
| JavaScript | Python2 | Python3 | Julia | Ruby |
|---|---|---|---|---|
| 9.62 | 93.08 | 23.94 | 1.46 | 19.44 |
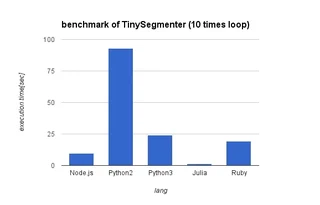
[追記ここまで]
| JavaScript | Python2 | Python3 | Julia | Ruby |
|---|---|---|---|---|
| 121.04 | 92.85 | 29.64 | 12.36 | (933+) |
メタメタした実装で遅すぎたRubyを外したグラフはこちら。
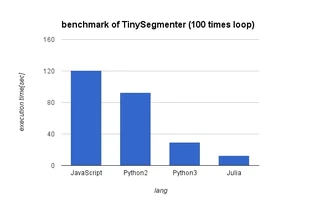
最適化をしたJuliaは確かに速いです。 そして、意外だったのはPython 3.5.0の速度。Unicode周りの実装が刷新されたという話は聞いていましたが、Juliaの二倍程度に肉薄してくるとは。条件にもよるかもしれないけど、文字列処理するNLPerは3系に今すぐ移行したほうが良いのでは?と思いました。
最後に、SGJ先生はjulia-usersのMLに成果を投稿していただきました。 なんか、一人JSoCって感じですね。
まとめ
- Juliaでパッケージを作ると、MITの先生が指導してくれる
- Julia速いけどCharacter辛い
- Pythonは3.5.0に今すぐ移行しないと!
というわけで、今後はC++やgoと比較するためにTinySegmenterMakerのJulia template作って比較したいね、と話しています。TinySummarizerにもtryしたいなぁ。
12/19(土)に Julia Tokyoの第5回ミートアップが開催されます! いつもJuliaはじめて24時間枠の発表もあるので、お気軽に参加・発表しに来て下さい!

