
4 Steps to Release a CLI in Python
This is what I learned from creating a Python CLI (digdaglog2sql) in a day. In just 4 steps, you can release a CLI written in Python easily. Create a project by using poetry Poetry …
This is what I learned from creating a Python CLI (digdaglog2sql) in a day. In just 4 steps, you can release a CLI written in Python easily. Create a project by using poetry Poetry …
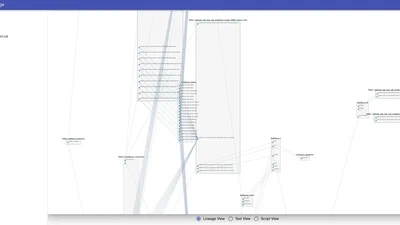
What’s data lineage? Data lineage is something to describe “Where this data comes from and where it goes?” I learned this term in my previous job. They provided “Cloudera …
Hugo has a feature to show keyword based related articles. Yeah, keyword based articles might be useful, for people who can manage keyword, category, etc, constantly. I’d love to …
This article show how to develop a digdag Python workflow task efficiently.
Recently, I changed my CI from Travis to GitHub Actions. GitHub Actions is handy and useful for testing, publishing Python packages.
Testing workflow runnability would be important when we build a complex workflow. digdag is a workflow engine which syntax is simple and…
I attended OpML ’19 is a conference for “Operational Machine Learning” held at Santa Clara on May 20th.
I attended RubyKaigi 2019 held at Fukuoka from Apr 18 to Apr 21. This year’s RubyKaigi was a really great opportunity for me to know the…
This article is a repost of Patreon article published last December. I’m planning to bump up next version of tabula-py within few weeks.
Yesterday, PyPI was renewed to the next-generation site. It is modern and stylish one.