tabula-py: Extract table from PDF into Python DataFrame
(Oct 7th, 2019) As of Oct. 2019, I launched a documentation site and Google Colab notebook for tabula-py. The FAQ would be good place to execute accurate extraction.
Screenshots in this article is based on the old version interface. See the latest version example in the Colab notebook.
Today, I released tabula-py 0.3.0, which extracts table from PDF into Python pandas’s DataFrame.
It is simple wrapper of tabula-java and it enables you to extract table into DataFrame or JSON with Python. You also can extract tables from PDF into CSV, TSV or JSON file.
tabula is a tool to extract tables from PDFs. It is GUI based software, but tabula-java is a tool based on CUI. Though there were Ruby, R, and Node.js bindings of tabula-java, before tabula-py there isn’t any Python binding of it. I believe PyData is a great ecosystem for data analysis and that’s why I created tabula-py. If you are familiar with R, I highly recommend to use tabulizer, which has the most richest bindings including rich GUI.
You can install tabula-py via pip:
pip install tabula-py
With tabula-py, you can get DataFrame with read_pdf() method.
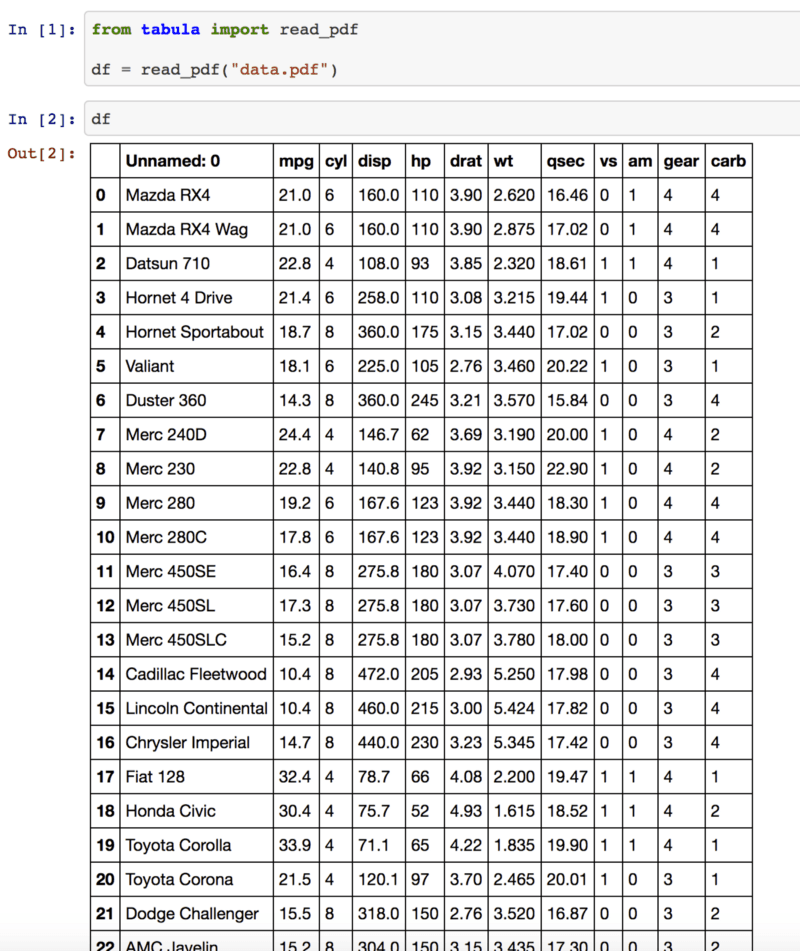
example of read_pdf()
read_pdf()
You can also extract tables as JSON format:
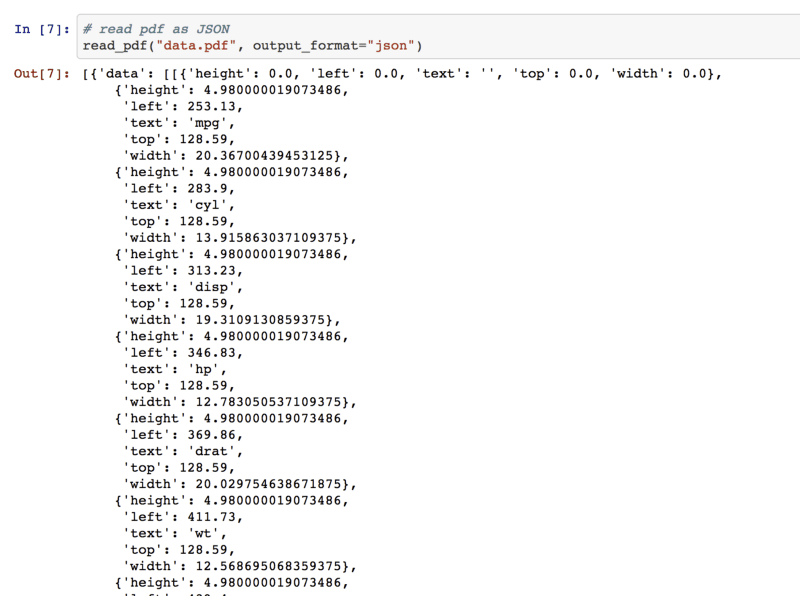
example of JSON
You can extract tables into a file like JSON, CSV or TSV with convert_into() method.
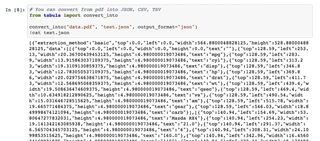
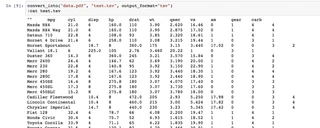
You can see more examples in Jupyter notebook.
I hope you will enjoy data wrangling with tabula-py. Any feedback would be welcome!
Waiting for your collaboration!
If you have any trouble with tabula-py, please file an issue on GitHub. I don’t want to receive emails because the answer will not share with other people. Make sure to fill the issue template, it will reduce many costs for me to solve the problem. Or, I also check StackOverflow. You can ask about it.

